
Buying a pre-owned domain name, deploying a CDN, using Bootstrap CSS classes, utilizing robots.txt – sounds innocent enough? They could be the cause of your SEO woes! Some of these points might sound like common sense, but they are real problems that have had significant impact in some projects we’ve come across.
Pure Spam?!
Has your site been labelled as Pure Spam? This is a death sentence to any kind of SEO efforts that you may have been working on. Your site probably won’t even be listed for any kind of search. To check if your site has any issues, add your site and all its variations (e.g. searix.net and www.searix.net) to Google Webmaster Tools, and read the “Manual Actions” tab.
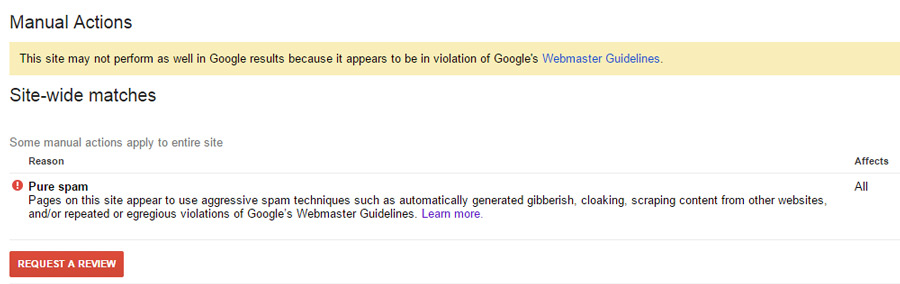
So what innocent practices could cause Google to classify your website as Pure Spam?
Innocent Practice #1 – Using CSS to hide content
One of our clients had designed a site with lots of pre-filled content in their prototype website. Before moving to production, they applied the Bootstrap CSS “hide” class to a whole block of content that they were going to save for a later time. This is also equivalent to using:
display: none;
This particular block of content took up about 70% of the code on the index page, was unintentionally keyword-rich (sample titles and excerpts of blog articles related to the industry), and did not have mechanism of any kind (manual or automatic) to make that content visible to the end user.
Google apparently doesn’t algorithmically mark such a practice as spam. Although Matt Cutts wrote that a decade ago, it still makes sense because the “Pure Spam” notification was quick to appear under the “Manual Actions” tab.
Remember: Hiding content with CSS should only be done if that content is going to be visible somehow, whether via a user’s action, or an automatic trigger. If that’s not going to happen, comment the code or remove it entirely.
Innocent Practice #2 – Buying a pre-owned domain name
Another one of our clients’ site was marked “Pure Spam” right from the start, once it was added to Google Webmaster Tools. But how could that be?
Remember that annoying ex you had with all the baggage and unnecessary drama? It’s pretty much the same thing happening here. This client purchased a domain name that used to be spammy and probably got classified as “Pure Spam” then. Since this is a manual action, it wasn’t automatically removed after the ownership change.
This is a more common oversight than you’d think – ZDNet burned the bridge before crossing it, and only realized it too late.
The solution is a simple one – verify that the old domain used to be spammy using the Wayback Machine, then submit a reconsideration request explaining so, and be polite about it.
Remember: Do your due diligence on the domain name you’re purchasing. If you expect an issue like this to arise, add the domains to Google Webmaster Tools to resolve it first, before deploying your site.
Using a CDN wrongly might negate all SEO efforts
Are you thinking of using a CDN to deploy your AJAX website or application? It was one of our client’s first time doing so – they used jQuery’s AJAX methods and AWS CloudFront, and made many misconfigurations. This ultimately cost them over 3 months of poor performance on Google’s results listing.
There are three popular ways of serving pages to search engine crawlers / robots – escaped fragment, pre-rendering and Javascript.
Innocent Practice #3 – Not Forwarding Query Strings
The escaped fragment method for providing content to search engine crawlers has this format:
http://example.com/?_escaped_fragment_=key=value
The hash string following the escaped_fragment represents AJAX app states. Ideally, each dynamic, AJAX-loaded page should have a corresponding AJAX app state. Google has the whole set of specifications written out.
To opt into this AJAX crawling scheme, webmasters have to put this line of code in each page’s code –
<meta name="fragment" content="!">
A CDN’s default settings might include not forwarding query strings to improve the caching performance. Unfortunately, this also means that if you are using this AJAX crawling scheme, the CDN is not passing the ?_escaped_fragment_ portion of the transformed URL to Google and none of your AJAX will get rendered.

Remember: If your website utilizes the _escaped_fragment_ AJAX crawling scheme, make sure your CDN forwards query strings.
Innocent Practice #4 – Not Forwarding User Agents
Pre-rendering relies on checking user-agent strings in the HTTP headers to find out if a search engine crawler / bot is crawling the page, then serving a static page specially for them so that those which do not render Javascript well may still get the content. A common option would be to use prerender.io, which uses PhantomJS / CasperJS / ZombieJS.
How does a user-agent string look like? Google’s something like this –
“Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
A CDN’s default settings might include not passing on this user-agent string in the headers. This would render your pre-rendering efforts entirely moot because your server wouldn’t even know that it’s a search crawler attempting to access your site and will therefore not serve a pre-rendered page.
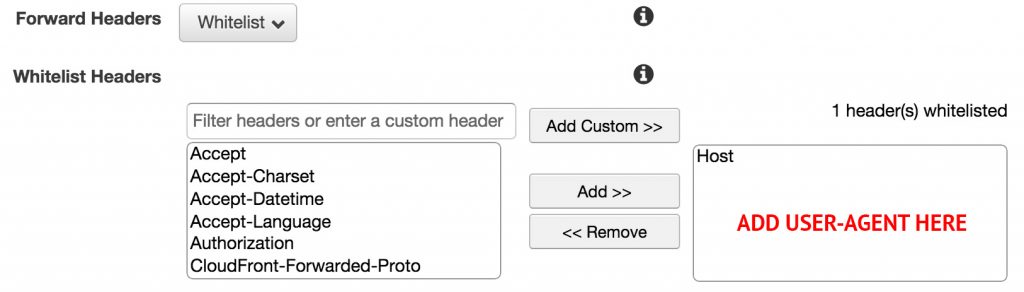
Remember: If you opt for pre-rendering Javascript pages, make sure your CDN passes on user-agent strings.
Robots.txt can be your worst nightmare
It’ll be your worst nightmare because it seems so innocent, that you might not actually think that it’s a problem at all. Sneaky sneaky. One of our clients struggled with this for a whole month before seeking help.
Innocent Practice #5 – Disallowing all on your API URL
The last method of serving Javascript-enabled pages relies on search engines supporting Javascript (d’oh), this is the easiest to implement even if your site uses AJAX.
{kind=link}
This client had 2 URLS – www.example.com and api.example.com, with the API serving AJAX routing URLs. However, they had this in their robots.txt on api.example.com –
User-agent: * Disallow: /
Disallow rules are commonly used to prevent search engine from indexing specific portions of a site.
Having a “disallow all” rule might seem acceptable for an API because you might not expect Google to index or serve data from the API. However, used in combination with AJAX pages, GoogleBot is not able to render pages because it prevents GoogleBot from accessing AJAX specific routing urls.
As a result, all the AJAX-enabled pages were not loading for Googlebot, and nothing was getting indexed.
Remember: If your API serves routing URLs, do not block it on robots.txt
That’s a lot to remember / TL;DR
- Hiding content with CSS should only be done if that content is going to be visible somehow, whether via a user’s action, or an automatic trigger. If that’s not going to happen, comment the code or remove it entirely.
- Do your due diligence on your domain name purchase and add it to Google Webmaster Tools early.
- If you’re ever in doubt of whether your Javascript / AJAX is rendering correctly, “Fetch as Google” is your best friend.
Can we help you with your website or SEO / digital marketing problems? Let us know!
This article has been reposted on Tech In Asia.