
Google Dance just happened in Singapore for the very first time 3 days ago, on 26th July. It was a gathering of website owners, webmasters and web developers, hosted by the Google Search team. The term “Google Dance” used to describe a period of time when Google used to rebuild its rankings, causing ranking results to fluctuate wildly (like a dance) for a few days. About 200 people from Singapore, Malaysia, Indonesia, Vietnam, Thailand, Japan and probably a couple more other countries turned up, and it was an afternoon of knowledge sharing by the Google Search team.
 The first talk was an introduction by Juan Felipe Rincón (@jfrprr), followed by Gary Illyes (@methode), Webmaster Trend Analyst at Google.
He re-confirmed a things about ranking signals that we already know, including –
The first talk was an introduction by Juan Felipe Rincón (@jfrprr), followed by Gary Illyes (@methode), Webmaster Trend Analyst at Google.
He re-confirmed a things about ranking signals that we already know, including –
 Furthermore, he encouraged the less-emphasized optimizing for Google Image Search (especially by using alt-text, adding captions and lazyloading with the <noscript> tag), for speed (using a tool like Lighthouse), and for Structured Data.
If your page navigation / content is dependent on Javascript, Gary had more to say –
Furthermore, he encouraged the less-emphasized optimizing for Google Image Search (especially by using alt-text, adding captions and lazyloading with the <noscript> tag), for speed (using a tool like Lighthouse), and for Structured Data.
If your page navigation / content is dependent on Javascript, Gary had more to say –
Stacie Chan (@staciechan), Global Product Partnerships Manager at Google, was up next, talking about Search Partnerships.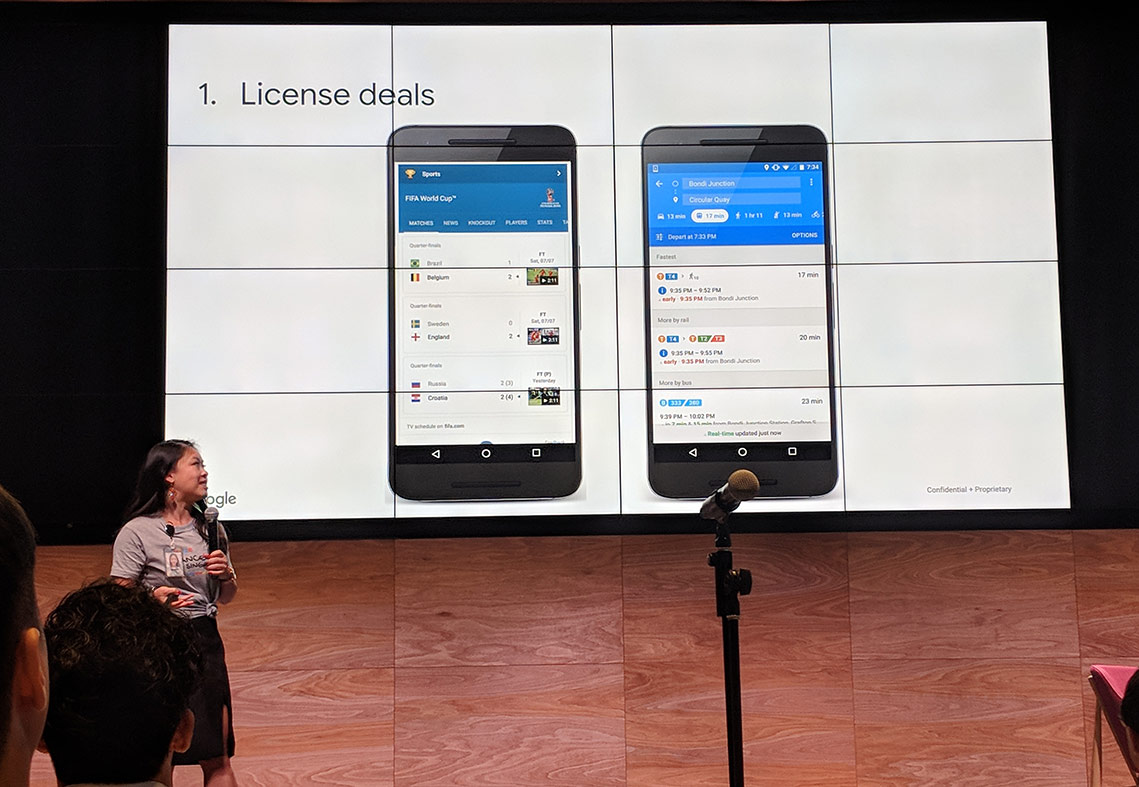 She shared how Google has established Search Partnerships in various ways, including
She shared how Google has established Search Partnerships in various ways, including
 Stacie is looking out for partners to try out these implementations and because the guide to implementing these is not publicly available, you should approach her if you are interested in implementing them.
Stacie is looking out for partners to try out these implementations and because the guide to implementing these is not publicly available, you should approach her if you are interested in implementing them.
Then, Yinnon Haviv, Software Engineer for the Search Console, ran through some features of the new Search Console, and also shared some of the issues the product team faced in developing it. The main takeaways –
The main takeaways –
Finally, there was a panel discussion that Lucian Teo (@lucian) moderated. Confession: I actually integrated answers to quite a few of the questions into the points above. But one response that stood out was for a question that went like this – “What is one thing that webmasters tend to leave out in their quest for optimizing web presence?” Gary’s answer – “Content”.
I’ve definitely missed out a couple of things here and there, but overall it was a great event and I definitely look forward to the next one, hopefully in Singapore again.
The first talk was an introduction by Juan Felipe Rincón (@jfrprr), followed by Gary Illyes (@methode), Webmaster Trend Analyst at Google.
He re-confirmed a things about ranking signals that we already know, including –
- There are over 200 factors taken into consideration
- The presence of explicit content is one of them
- Geographical localization is another one
- PageRank is still very well and alive – it’s only not shown on the Google toolbar anymore
- The usage of AMP in itself is not a ranking signal, but the resultant improvements in page loads, etc. are
- Having too many advertisements on a page is considered a negative signal
- If you want to torture yourself (or your intern), check out the recently-updated (20th July) Page Quality Rating Guidelines – there might be some glimpses of enlightenment there
Furthermore, he encouraged the less-emphasized optimizing for Google Image Search (especially by using alt-text, adding captions and lazyloading with the <noscript> tag), for speed (using a tool like Lighthouse), and for Structured Data.
If your page navigation / content is dependent on Javascript, Gary had more to say –
- Currently, Googlebot uses Chrome 41, with no ES6 and no storage APIs
- Rendering happens after crawling, and before indexing
- Following Javascript links is slower
- rel-canonical is always read from the static content, where as the meta title and description can be picked up post-rendering
- Googlebot renders 12,140px high on mobile and 9,307px high on desktop, but there is a lower limit on the width. This might be of concern to you if you have a long carousel / slider
- To overcome that problem, Gary suggests sticking to a vertical slider but using CSS to display it horizontally
- Generally, single-page applications (SPA) pose a problems to search engines
- The idea is that there should be a single unique URL (excluding the # symbol and everything after it, a.k.a. fragment identifiers) for every page of content
- If your app displays content based on fragment identifiers, chances are that the rendering isn’t effective and your site isn’t indexed well
- Always test using the Fetch & Render in the Search Console. The result is 1-to-1
- Most of the current index is still on desktop content, but the transition to mobile content is happening
- If your site uses a hamburger menu, it’s fine.
- If your site uses fold-out content (e.g. tabs), it’s fine too
- You have options of creating a separate URL (e.g. m.site.com), doing dynamic pre-rendering, or a creating responsive site
- If you create a create a separate site, ensure that the meta content and structured data remain the same
Stacie Chan (@staciechan), Global Product Partnerships Manager at Google, was up next, talking about Search Partnerships.
She shared how Google has established Search Partnerships in various ways, including
- License Deals, e.g. FIFA being recognized as the formative authority on World Cup results, or the Land Transport Authority being recognized as the authority on transport timings
- EAP (Early Adopter Program) Partnerships, e.g. encouraging the adoption of new products, e.g. the recipe Schema tag, control over Knowledge Panels, and the new Search Console
Stacie is looking out for partners to try out these implementations and because the guide to implementing these is not publicly available, you should approach her if you are interested in implementing them.
Then, Yinnon Haviv, Software Engineer for the Search Console, ran through some features of the new Search Console, and also shared some of the issues the product team faced in developing it.
The main takeaways –
- There’s a much tighter feedback loop now, especially with regards to crawl and indexing errors
- There’s also an ability to share specific issues and detailed information about them with developers throguh a “Share” button
- Search Console (especially the Performance report) is now mobile-friendly
- There’s full API access to 16 months of data, and if there’s a need for more, provide feedback with use cases them
- There’s also an effort to start recognize apps as properties, and also to refine deep-linking attributions
Finally, there was a panel discussion that Lucian Teo (@lucian) moderated. Confession: I actually integrated answers to quite a few of the questions into the points above. But one response that stood out was for a question that went like this – “What is one thing that webmasters tend to leave out in their quest for optimizing web presence?” Gary’s answer – “Content”.
I’ve definitely missed out a couple of things here and there, but overall it was a great event and I definitely look forward to the next one, hopefully in Singapore again.